

以客戶為(wèi)中(zhōng)心,提供定制化或一站式的全棧解決方案,賦能(néng)千行百業

GPU計算是指利用(yòng)圖形卡來進行一般意義上的計算,而不是傳統意義上的圖形繪制。時至今日,GPU已發展成為(wèi)一種高度并行化、多(duō)線(xiàn)程、多(duō)核的處理(lǐ)器,具(jù)有(yǒu)傑出的計算功率和極高的存儲器帶寬。如圖:
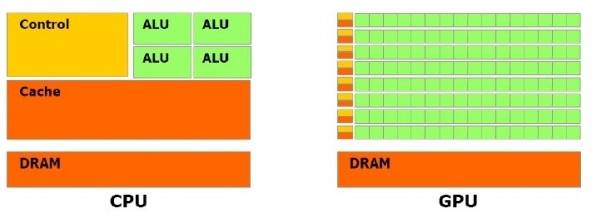
具(jù)體(tǐ)地說,GPU專用(yòng)于解決可(kě)表示為(wèi)數據并行計算的問題——在許多(duō)數據元素上并行執行的程序,具(jù)有(yǒu)極高的計算密度(數學(xué)運算與存儲器運算的比率)。由于所有(yǒu)數據元素都執行相同的程序,因此對精(jīng)密流控制的要求不高;由于在許多(duō)數據元素上運行,且具(jù)有(yǒu)較高的計算密度,因而可(kě)通過計算隐藏存儲器訪問延遲,而不必使用(yòng)較大的數據緩存。
數據并行處理(lǐ)會将數據元素映射到并行處理(lǐ)線(xiàn)程。許多(duō)處理(lǐ)大型數據集的應用(yòng)程序都可(kě)使用(yòng)數據并行編程模型來加速計算。在 3D渲染中(zhōng),大量的像素和頂點集将映射到并行線(xiàn)程。類似地,圖像和媒體(tǐ)處理(lǐ)應用(yòng)程序(如渲染圖像的後期處理(lǐ)、視頻編碼和解碼、圖像縮放、立體(tǐ)視覺和模式識别等)可(kě)将圖像塊和像素映射到并行處理(lǐ)線(xiàn)程。實際上,在圖像渲染和處理(lǐ)領域之外的許多(duō)算法也都是通過數據并行處理(lǐ)加速的——從普通信号處理(lǐ)或物(wù)理(lǐ)仿真一直到數理(lǐ)金融或數理(lǐ)生物(wù)學(xué)。在上述領域,GPU計算已經獲得了成功的應用(yòng),并取得了令人難以置信的加速效果。
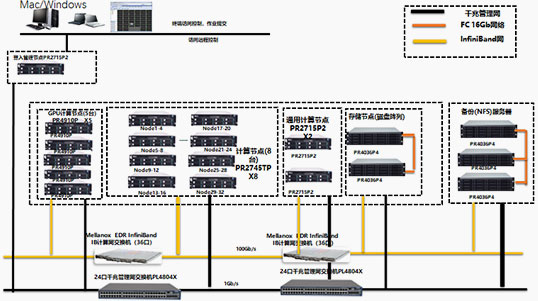
整套GPU高性能(néng)方案采用(yòng)通用(yòng)CPU和專用(yòng)GPU均衡設計,既保證了GPU的處理(lǐ)性能(néng),又(yòu)兼顧了通用(yòng)CPU的計算能(néng)力。既保證了适合GPU的高并行度計算應用(yòng)的需求,同時也保證了非高并行度應用(yòng)和尚未進行GPU移植的應用(yòng)需求。并且由于GPU具(jù)有(yǒu)較高浮點計算性能(néng)的特點,方案中(zhōng)使用(yòng)GPU作(zuò)為(wèi)主體(tǐ)計算資源,将圖形處理(lǐ)器引入到高性能(néng)計算領域。

GPU計算節點使用(yòng)了寶德(dé)PR4910P,該機型有(yǒu)着超高的擴展性,GPU方面最多(duō)支持到10個全高全長(cháng)的GPU插槽。同時支持多(duō)種的網絡支持,可(kě)實現增強的高速性能(néng)和 I/O 靈活性,滿足不同應用(yòng)程序的互聯需。
存儲節點采用(yòng)了寶德(dé)PR4036P4機型,具(jù)有(yǒu)高可(kě)擴充性和高可(kě)用(yòng)性,能(néng)夠解決數據爆炸性增長(cháng)帶來的存儲挑戰,并且支持智能(néng)陣列,顯著增強I/O性能(néng)和數據的安(ān)全性。
在網絡通信方面所有(yǒu)節點通過高速的Infiniband網絡連接,實現節點之間的全互聯,大大降低節點之間的通信延遲,為(wèi)集群提供了一個高帶寬低延遲的IO和網絡數據交換性能(néng)環境。

系統支持CPU和GPU的混合計算。系統具(jù)有(yǒu)較高的計算密度,可(kě)在實現超過500TFlops(單精(jīng)度)的計算能(néng)力,同時具(jù)有(yǒu)良好的可(kě)擴展性,能(néng)夠輕松擴展到千萬億次。
GPU節點、存儲節點、計算節點等有(yǒu)很(hěn)高的擴展性,既能(néng)滿足現階段的業務(wù)要求,也能(néng)更具(jù)未來業務(wù)量的增長(cháng)進行升級和擴容。
寶德(dé)通過統一的集群管理(lǐ)、作(zuò)業調度,結合寶德(dé)高性能(néng)的服務(wù)器,從各個方面提高整套系統的穩定性,大大提高用(yòng)戶的使用(yòng)穩定性同時減少了故障率。
服務(wù)超越
行業多(duō)年經驗的HPC專家可(kě)為(wèi)用(yòng)戶提供應用(yòng)級别的運維服務(wù),協助用(yòng)戶應用(yòng)調優,發現問題,提供專業的解決方案。

寶德(dé)服務(wù)器

寶德(dé)自強









 4008-870-872
4008-870-872
